IT業界において、2022年はいわゆる「Generative AI(生成型の人工知能)」が注目を浴びた年だった。
ディープラーニングなど従来のAIは基本的に各種データの「分析」に使われるが、生成型のAIは(同じくディープラーニング技術に基づくとはいえ)文字通り「画像」や「テキスト(文章)」、「コンピュータ・プログラム」など各種コンテンツを「生成」するAIである。この種の人工知能は今後、AIブームの第2波を形成していくことが期待されている。その動向を新たな連載コラムとして紹介していく。初回となる本稿では、まず2022年の夏頃から次々とリリースされた「画像を生成するAI」から見ていくことにしよう。
よく知られているところでは、米Stability AI社の「Stable Diffusion」と「DreamStudio」、米国の研究機関OpenAIの「DALL-E2」、同じく米国の研究機関Midjourneyがリリースした「Midjourney(組織名と製品名が同じ)」などがある。いずれも今のところベータ版(お試し版)という位置付けにあり、一部は期間限定など若干の制限はあるものの概ね無料で使える。
これら画像生成AIではウェブ・サイトの空欄に自然言語、つまり私達が普段使っている言葉で描きたい画像をリクエストすると、それに該当する(写真あるいは絵画風の)画像が生成される。いずれも英語のみならず日本語のような(米国から見て)外国語にも対応しているが、やはり英語で入力するのが最も的確にリクエスト画像を描き出すことができるようだ。
筆者も試しにDreamStudioを使って「a dog and a man are playing Frisbee」というリクエストを出してみた。それに該当する画像が描き出される様子は以下の通りだ(図1)。
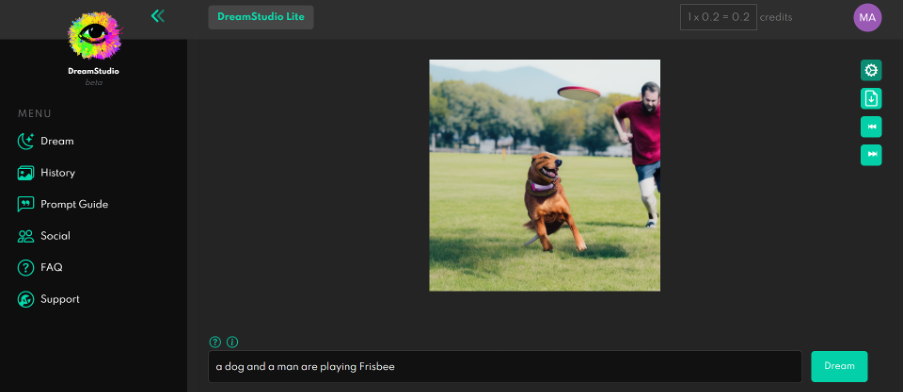
出典:https://beta.dreamstudio.ai/dream
本当は誰(何)が画像を描き出しているのか?
このようにして生成された画像の著作権が気になるところだが、作品の利用について制限される場合もあれば、基本的に自由に使って構わない場合もある。つまりマチマチである。
恐らく最も自由に使えるのはStability AI社のツールであろう。同社は「AIの民主化」をモットーに掲げており、同社製のツールであるStable DiffusionやDreamStudioで生成された画像を、ユーザーが自分のホームページに掲載したり、ソーシャルメディアに流したりすることを全く制限していない。
「たとえAIというツールを使うとはいえ、ユーザーが自分で製作した画像である以上はその著作権はユーザーにあるはず。自由に使えるのは、むしろ当然ではないか」と思われるかもしれないが、その辺りが実は微妙なのである。そもそも「画像を生成する」と言っても、実際に多くのユーザーがやっていることは(筆者がやったように)簡単な文章で何らかの画像をリクエストするだけだ。
また、この種のAIが実際に行っていることは、ウェブ上から各種の画像データを大量に収集して、それらを機械学習(ディープラーニング)することによって、ある種のパターン(描画スタイル)を導き出すことだ。
これらのパターンをベースに新たな画像を生成するわけだが、それが厳密にオリジナルの創作活動と呼べるかは(少なくとも現時点では)賛否両論が聞かれ、一致した見解があるわけではない。
生成される画像のクォリティもマチマチである。筆者が発したような簡単なリクエストだと、生成される画像もそれなりのものしか出力されない。これとは対照的に、たとえば「シュールレアリスム風の細密画」などクォリティの高い画像を生成することも可能だが、そのためにはかなり長い時間をかけて、試行錯誤を繰り返しながら綿密な言語的指示を出す必要がある。
つまり画像生成AIを使って良いものを作り出すには、それなりのテクニックが必要とされる。この点では、これらの画像を制作したユーザーが自分の著作権を主張したくなったとしても理解できる。
AI作品が芸術祭で入賞
この点について物議を醸した出来事があった。
2022年の夏、米国のコロラド州で開催された地場祭典・展示会「Colorado State Fair」のデジタル・アート部門で、画像生成AIによって製作された作品が賞金300ドル(約4万円)の優秀賞を受賞した。
フランス語で「Théâtre D’opéra Spatial(スペースオペラ劇場)」と命名された同作品は、同州在住のジェイソン・アレン氏がMidjourneyを使って製作したものだ。本稿では実物をお見せできないが、この作品に描かれているのは、確かにスペースオペラ風の、かなり手の込んだ細密画である(スペースオペラはSFの1ジャンルで、たとえば「スターウォーズ」のような宇宙を舞台にした大活劇のこと)。
アレン氏の職業はアート・スタジオの経営者であり、プロの画家ではない。しかし、ふとしたきっかけでMidjourneyを使い始め、それにはまってしまった。以来、何百点もの画像をAIで製作するうちに、どんどん腕が上がっていった。そのうちの1枚をプリントアウトして上記展示会に出品したところ入賞することができた。
アレン氏は展示会に作品を出品する際、「AIで製作した」ということを主催者側に包み隠さず伝えたという。つまり展示会の審査員も、それと知ったうえで賞を授与したことになる。
しかし、この一件がソーシャルメディア等を通じて世間に知れ渡ると激しい論争が巻き起こった。たとえばツイッター上には「今、我々が目にしているのは芸術の死だ」「ぞっとする。こんなものを作っただけで自分を芸術家だと思うな」など手厳しい意見が寄せられた。
その一方で、アレン氏の行為を擁護する見解も聞かれた。Midjourneyのような画像生成AIを使って作品を製作することは、(アドビの)「イラストレーター」や「フォットショップ」のような画像編集ツールを使って製作することと本質的に同じだというのだ。
「画像編集ツールではマウスやキーボード、ペンタブレットなどを使うが、画像生成AIではそれが人間の言葉に置き換わっただけ。真の芸術性はそれらの操作によって表現される作品自体にある」というわけだ。
因みにアレン氏はMidjourneyで「Théâtre D’opéra Spatial」を製作する際に、どのような言葉(文章)でそれをリクエストしたかを明らかにしていない。また仮にそれが明らかにされ、それと全く同じ文章でリクエストしたとしても、全く同じ作品が出来上がるとは限らない。MidjourneyのようなAIはある種の確率的なプロセスに従って画像を描き出すので、その作品には偶然性がつきまとうのである。
人間の道具にはなるが職は奪わない
以上のように未だ評価の定まらない画像生成AIだが、既にプロのデザイナーやアーティストらがこれを使い始めている。
たとえば米サンフランシスコ在住のインテリア・デザイナー(女性)は、某クライアントから依頼されたオフィスの内装デザインを「Interior AI」という画像生成AIを使って行ってみた(1)。
その際、言葉による綿密なリクエストと同時に、このツールに組み込まれている「サイバーパンク」と呼ばれるフィルターを通して描いてみたところ、幻想的な照明や丸みを帯びた奇妙な形のソファーなど、いかにもサイバーパンク風のオフィスを描き出した画像が生成されたという。
ただ、この画像はそのままクライアントに提出するには、あまりにも粗削りな出来であった。つまり最終的にはデザイナー(人間)による調整が必要と見られたのである。
画像生成AIはプロジェクトの初期段階で、ラフなアイディアを提示してくれるという点で役立つが、それを調整して最後に作品を完成させるのは人間の役目ということになる。その際、クライアント(こちらも人間)がどのようなデザインを好むか、つまり作品の微妙な「タッチ(細部の作風)」は結局デザイナーのような人間にしか理解できない。
こうした点でAIは人間の道具にはなっても、その仕事を奪うことはなさそうだ。そう彼女は見ている。
こうしたプロと共に、一般ユーザーの間にも画像生成AIは浸透し始めている。中でも米Prisma Labs製のスマホ用アプリ「Lensa AI」は爆発的な人気を呼んでいる。
同アプリはStability AI社のStable Diffusionをベースに開発されたものだ。前述のように「AIの民主化」をモットーに掲げるStable AIはStable Difffusionをオープン・ソースとして公開しているので、Prisma Labsのような別の会社がそれをベースに別の製品を作り出すことが可能なのだ。
自撮り写真のアバター化が人気
こうして出来上がったLensa AIには様々な機能が搭載されているが、ユーザーの間で最も人気が高いのは「Magic Avatar」と呼ばれる機能だ。これはユーザーがスマホで撮影した自撮り写真、いわゆる「セルフィー」を大胆に加工して、極めて印象的なポートレイト(肖像画)を作り出すことができる。ユーザーが一般に「盛る」と呼んでいる行為だが、その過程でStable Diffusionをベースとする画像生成AIが使われているのだ。
ただし、Lensa AIでは他の画像生成AIのように自由な言葉で自撮り写真を編集することはできない。その代わりに「Fantasy」「Anime」「Pop」「Stylish」「Sci-fi」など何種類もの描画スタイルが用意されている。ユーザーが自撮り写真をLensa AIで処理すると、各スタイルに従って加工されたポートレイト(アバター)が何枚もスマホ画面にスライド形式で表示される。
ただし全く同じ自撮り写真に全く同じスタイルが適用されても、全く同じ描画結果が出力されるとは限らない。他の画像生成AIと同じく、Lensa AIでも確率的なプロセスに従って画像を描き出すので、出来上がったものには偶然性が付きまとう。つまり「結果は見てのお楽しみ」と言ったところだが、こうしたワクワク感も多くのユーザーを惹きつける理由の一つと見られる。
このようにスマホ画面上に表示された多数のポートレイトの中から、ユーザーが好きなモノを選び出してスマホの記憶装置に保存したり、ソーシャルメディアにアップしたりすることができる。
Lensa AIのMagic Avatarは有料サービスだ。アバター1枚につき概ね4〜8セントが課金されるが、様々な使用条件に応じて価格は変動するようだ。
Magic Avatarは米国を中心に若者の間で絶大な人気を博す一方で、ユーザーの自撮り写真がときに「肌の色」や「体形」等の点で偏った方向に編集されるなど、ある種の問題も抱えている。たとえば肌の色は実際よりも白く、体形は実際よりも細くなる傾向があるという(2)。
これはウェブ上で収集された大量の画像データをMagic Avatarが機械学習する過程で、そのような傾向を自然に学び取ってしまったためと見られる。これを好むユーザーもいれば、逆に自分が侮辱されたような気がして気分を害するユーザーもいるという。
こうした点も含めて画像生成AIへの社会的な評価が確定するまでには、いましばらくの時間がかかりそうだ。
KDDI総合研究所リサーチフェロー 小林 雅一
 参考文献
参考文献
(1) “A.I.-Generated Art is Already Transforming Creative Work,” Kevin Roose, The New York Times,Oct. 21, 2022
(2)”How Is Everyone Making Those A.I. Selfies?” Madison Malone Kircher and Callie Holtermann, The New York Times, Dec. 7, 2022