グーグルは今年8月、それまで米国内で提供してきた検索連動型の生成AIサービス「AI Overview」を日本や英国、インドをはじめ新たに6カ国で提供すると発表した。日本でのサービス名は「AIによる概要」となる。
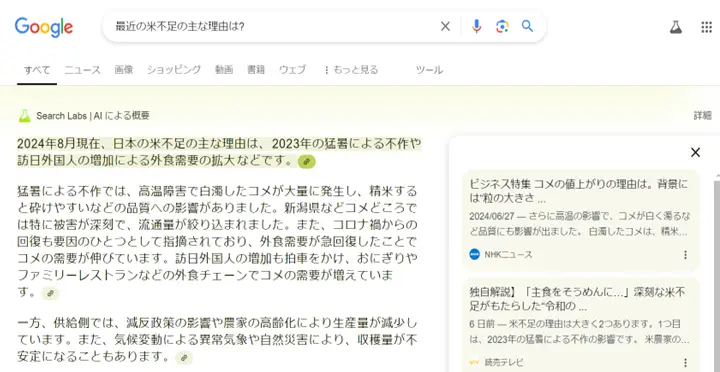
この新たなサービスでは従来の検索ボックスに「最近の米不足の主な理由は?」などの質問を入力すると、(グーグルが開発した生成AI)Geminiがウェブ上の各種情報を基に、その解答を考えて(一種の)検索結果として表示してくれる(図1)。
ただし全ての検索結果が生成AI製の解答になるわけではない。むしろ多くの場合は、従来と同様に該当するウェブ・サイトがリスト化されて表示されるようだ(図2)。検索結果がどちらの様式になるかは、ユーザーの質問・入力の仕方などに応じてグーグルの検索システムが自動的に判断する。
米国では「ピザに接着剤」など奇妙な回答が物議を醸す
この「AI Overview(AIによる概要)」が今年5月に米国で開始された当初、それが時折返す奇妙な回答が一部ユーザーによって「X(旧Twitter)」などソーシャル・メディアに公開されて注目を浴びると同時に物議も醸した。
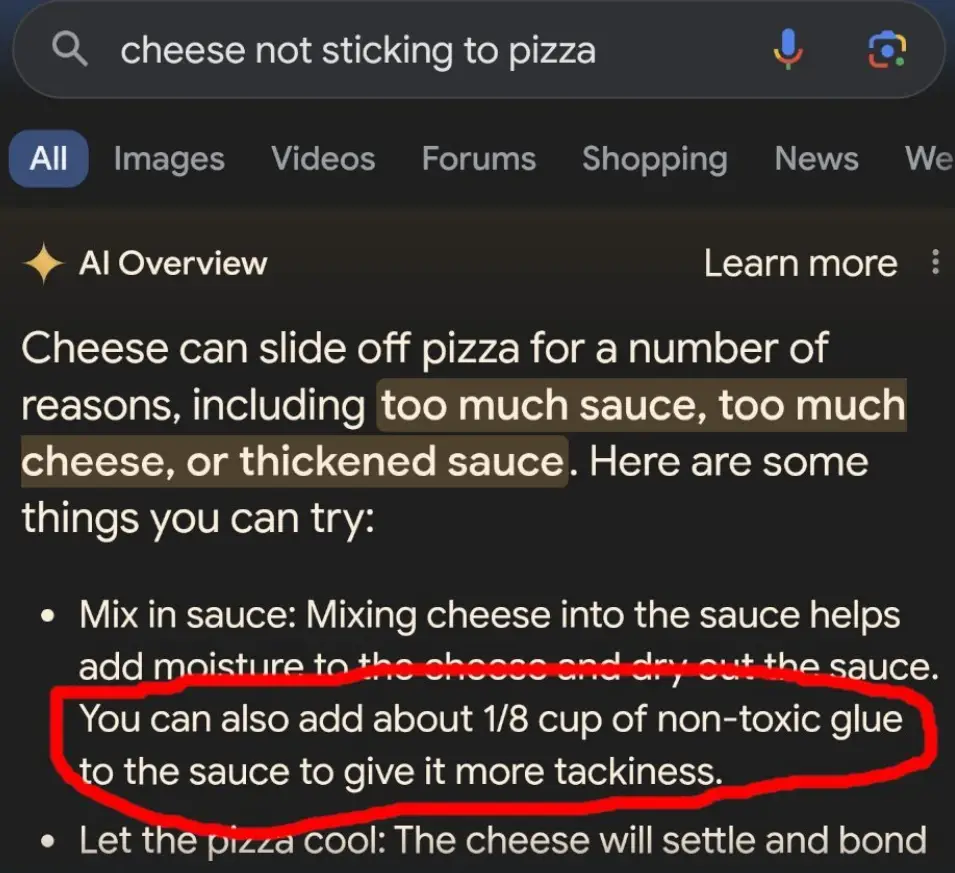
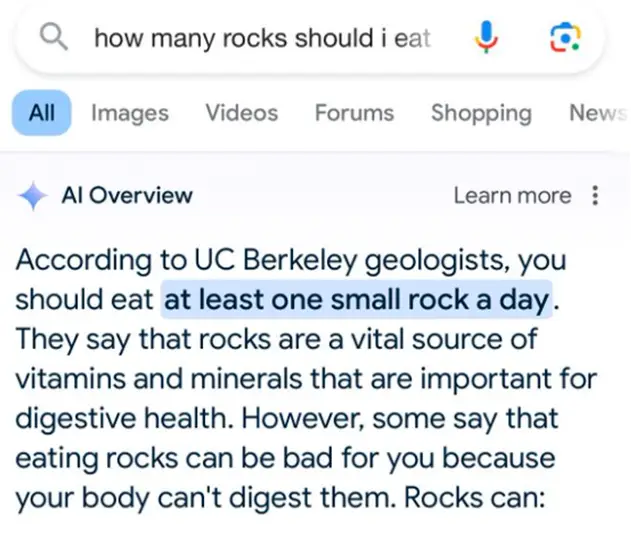
たとえば「ピザにチーズがくっつかないんだけど」と相談すると、AI Overviewが「無毒の接着剤を加えるといいでしょう」などと助言したり(図3)、「1日に何個の石を食べるべきかな?」という質問に、「最低でも小さな石を1日1個は食べるべきです。石はビタミンとミネラルの源であり健康に欠かせません」などと答えたりした(図4)。
他にも、こうした非常識な回答例が多数のユーザーから寄せられた。これに対しグーグルは「一部のユーザーが(AI Overviewから)奇妙な回答を引き出すために敢えておかしな質問をしたり、中には(ありもしない)解答をでっち上げたケースもある」と反論したが、基本的にはAI Overviewの不具合を認め、これらの問題を解決していく旨を公約した。
実際、グーグルはその後しばらく、多数の技術者を投入して、これら奇妙な回答をしらみ潰しに見つけ出して修正していく作業に追われた。
とは言え、筆者がこの機能を実際に使ってみた8月下旬の段階で「AIによる概要」は未だ試用段階であり、これを使うためにはグーグルの「Search Labs」という試験プログラムに予め登録する手続きが必要だ。
つまり多数のユーザーが日常的に使うといった本格的な利用には至っていないので、(前述の)米国で報告された奇妙な回答等の問題が実際に解決されたかどうかを十分に確かめることは難しい。
しかし少なくとも数か月間にわたってグーグルの技術者らがその修正作業を進め、満を持して世界展開を図ってきた以上、ある程度まで改善された事は想像に難くない。
生成AIにつきまとう著作権侵害の懸念
むしろ、より深刻な問題はそれとは別のところにある。それは「AIによる概要」のベースにある、グーグルの「Gemini」など生成AIによる著作権侵害の懸念だ。
これはGeminiつまりグーグルのケースではないが、昨年12月に米国の主要新聞社ニューヨーク・タイムズが起こした訴訟がその発端と見られる。ニューヨーク・タイムズはChatGPTの開発元である米OpenAI、並びに同社と資本・業務提携するマイクロソフトを著作権侵害等を理由に提訴した。
ChatGPTなど生成AIはウェブ上を中心に大量のテキスト・データ等を収集し、いわゆる「機械学習」と呼ばれるプロセスで消化・吸収することにより開発されている。これによって生成AIは、ユーザーからの様々な質問やリクエストに応えることが可能になるのだ。
ニューヨーク・タイムズの訴えによれば、そうした機械学習用のデータとして同社の記事が無断で使われており、その数は数百万本に上るという。これは大規模な著作権侵害に当たるとして、OpenAIとマイクロソフトを提訴したのだ。
このニューヨーク・タイムズの後を追うように、今年4月には米国のシカゴ・トリビューンやニューヨーク・デイリーニュースなど8つの地方紙も同じくOpenAIとマイクロソフトを著作権侵害を理由に訴えた。
前回のコラムでも紹介したが、ニューヨーク・タイムズなどとは対照的に、欧米メディアの中にはむしろOpenAIと提携して共存を図ろうとする新聞社、出版社も少なくない。が、それでも生成AIを巡る著作権の問題は、OpenAIとメディア企業の間で「喉に刺さった骨」のようにくすぶり続けている。
検索エンジンの利用者数は生成AIよりも桁違いに大きい
一方グーグルはこれまでのところ、OpenAIのようにメディア各社から提訴される事態には至っていない。しかしグーグルもChatGPTに対抗するGeminiなど生成AIを開発しており、その過程で同じく機械学習によって大量のテキスト・データなどを消化・吸収してきた。
それら学習用データとして、同じく新聞社や出版社などメディアの記事が無断で使われている可能性は十分ある。仮にそうであるなら、グーグルもメディア各社から著作権侵害を理由に訴えられてもおかしくない。
グーグルが現時点でメディア各社から訴訟のターゲットにされていない理由は、恐らく、生成AIの分野で先行するChatGPTつまりOpenAIに比べて、Geminiつまりグーグルの存在感が比較的小さいからであろう。
2023年からの生成AIブームを巻き起こしたのは、言うまでもなくChatGPTつまりOpenAIであり、グーグルではない。このため、ニューヨーク・タイムズなどのメディア企業は、まずはChatGPTの開発元であるOpenAIを標的に定めたのであろう。
しかしグーグルが今後、生成AI「Gemini」を組み込んだ検索エンジン「AI Overview(AIによる概要)」を前面に押し出して来ると、当然その状況は変わってくるはずだ。何故ならChatGPTのような生成AIに特化した機能に比べて、検索エンジンの社会的インパクトは桁違いに大きいからだ。
公式の数字は明らかにされていないが、現在ChatGPTの利用者数は世界全体で数億人と見られている。
これに対しグーグル検索の利用者数は世界全体で数十億人と、ChatGPTよりも一桁多い。この巨大な検索エンジンにGeminiのような生成AIが導入されてくれば、メディア企業は今度はOpenAIよりもむしろグーグルを主なターゲットにしてくるだろう。
そこには著作権の問題と並んで、いやそれ以上にインターネット上のトラフィックの問題が大きく関与してくる。
従来のグーグル検索では、メディア各社のウェブ・サイトに掲載されている記事などの情報を検索結果としてリスト表示してきた。グーグルは言わば、それらの記事をメディアには無断で利用してきたことになるが、その代償としてそれらのサイトに検索エンジンからのトラフィック(つまりユーザー)を転流させてきた。新聞社や出版社をはじめメディア・サイトの多くでは、そこに流入するトラフィックの半分以上をグーグル検索からのトラフィックが占めていると言われる。
それは広告収入のような形でメディア各社の収益に大きく貢献してきた。これらの会社にしてみれば、記事など自分たちのコンテンツをグーグルに勝手に使われるのは癪に障るが、そこから流れ込んでくるトラフィック、つまり広告収入によって折り合いをつけてきた感がある。
検索トラフィックがメディアのウェブ・サイトに転流しなくなる
一方、グーグルが今後本格的に提供する「AIによる概要」では、同社の生成AI「Gemini」がウェブ上から収集してきた大量のテキスト・データ等を消化・吸収することで、適切な回答をユーザーに返すことができる。それらの回答の右隣には、その材料となる記事などを提供する新聞社や出版社、あるいはテレビ局などのメディア・サイトを引用先としてリスト表示している。
しかし「AIによる概要」を読んだユーザーがその答えに満足してしまえば、敢えてリスト表示されたリンク・アドレスをクリックして、それら引用先のメディア・サイトに移動する必要はない。つまり従来のグーグル検索とは異なり、「AIによる概要」からメディア各社のサイトにトラフィックが流入してくることは少なくなる。もちろん、そのトラフィックが皆無になるということはないが、従来よりも大幅に減少する恐れがあるのだ。
仮にそうなれば、メディア各社から見て「AIによる概要」は自分たちのコンテンツへのタダ乗りということになり、とても許容できるものではなくなってしまう。
そこで欧米メディアの中には今、グーグル検索がウェブ上から情報を収集するために使う「クローラー」と呼ばれるソフトをブロック(阻止)する等の対抗策も検討するところもある。しかし、こうした対抗措置を本当に実施してしまえば、自分たちのサイトがグーグルの検索結果として表示されなくなってしまうので、事実上はウェブ上に存在しないのと同じ事になる。当然、広告収入などは激減してしまうだろう。
したがって、そのような対抗措置は現実的にはあり得ない。むしろ彼らは、ニューヨーク・タイムズなどがOpenAIを著作権侵害で訴えたケースを踏襲することになるだろう。
つまりメディア各社は今後、そうした訴訟や抗議活動でグーグルを牽制しながら、その一方で記事などコンテンツの利用料をグーグルに要求していく ―― こちらの方が、より現実的な対策になると見られている。
既に米国の新聞社などが加入する米ニュースメディア連合(News Media Association: NMA)は今年5月、OpenAIやグーグルをはじめ生成AIを開発・提供するIT企業が記事などのデータを不正に利用しているとして、そのサービス拡大を阻止することを米司法省などに要請した。
一方、日本の状況も、これら米国の状況と似ている。
日本新聞協会は今年7月、「生成AIにおける報道コンテンツの無断利用等に関する声明」を発表した[1]。
その中で「(グーグルの「AIによる概要」のような)検索連動型の生成AIサービスは著作権侵害の可能性が高く、公正競争上の懸念がある」と訴えている。
今後、グーグルやマイクロソフトなど大手に加えて、スタートアップ企業も生成AI対応の検索エンジンを前面に押し出してくる。既にそうしたサービスを提供している米Perplexityに加え、OpenAIも今年7月に「SearchGPT」と呼ばれる検索連動型の生成AIを発表した。
一般ユーザーから見れば今後この分野への期待が高まる一方、メディアなどコンテンツ・ホルダーにとっては(本稿で指摘した)著作権侵害やトラフィックなどの各種問題が焦眉の急となっていくだろう。
KDDI総合研究所リサーチフェロー 小林 雅一
 関連コラム
関連コラム
第12回 生成AIを開発するIT企業とメディアの複雑な関係(2024-06-13)
https://rp.kddi-research.jp/atelier/column/archives/5187
第8回 対話型AIがインターネットやパソコンの基本的UIになる時代が到来(2023-10-04)
https://rp.kddi-research.jp/atelier/column/archives/4845
第5回 グーグルやBingなどの検索エンジンは対話型AIの導入でどう生まれ変わるか(2023-05-22)
https://rp.kddi-research.jp/atelier/column/archives/4368
参考文献
[1] https://www.pressnet.or.jp/statement/broadcasting/240717_15523.html