米グーグルは今月初旬に開催した開発者向けイベント「Google I/O」で、生成AIの技術を多彩な新製品に組み込んでいくことを強調した。
中でも注目を浴びたのは、同社の主力製品である検索エンジンへの取り組みだ。グーグルは検索に(生成AIの一種である)対話型AIの機能を組み込むことで、従来よりもダイレクトかつ的確にウェブ上から情報を入手できるようにする。
既に開発済みの試作版では、従来のような検索用キーワードではなく、たとえば「3歳未満の子供と犬を連れていく旅行には観光地AとBのどちらがいいでしょう?」といった形で質問用の文章を直接入力できる(図1)。
それに対し対話型AIがかなり分量のある文章の形で何らかの回答を返す。これを読んだユーザーが新たな疑問や確かめたいことなどが思い浮かんだら、回答の真下にあるフォローアップ用のボタンをクリックするとAIとのチャット・モードに入る。ここから、このトピックについてAIとの議論を深め、最終的に最も適切な情報を得ることができる。
対話型AIによる回答の右側と真下には、従来の検索エンジンと同様、質問や回答の内容に関連するウェブ・サイト(リンク)が表示される。これをクリックすれば、それらのサイトに移動して情報源を確認できる。いずれ実際に製品化、つまり一般ユーザーに公開される際には、この検索結果を表示する画面のどこかに広告が表示されることになる。
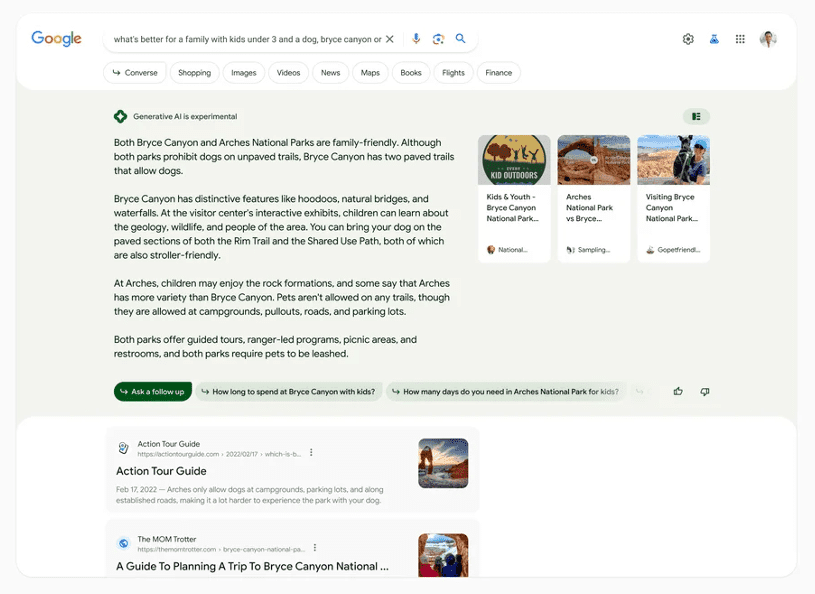
出典:https://blog.google/products/search/generative-ai-search/
グーグルは今後、ウェイティング・リストに登録した米国のユーザーに対し、この対話型検索エンジンを試験的に提供していく。今年末までに利用者数が約3千万人に到達することを目指している。日本をはじめ各国でリリースされるのは来年に入ってからかもしれない。
ビジネス・モデルは見えていない
ただ、問題はこうした新型検索エンジンのビジネス・モデル、つまりお金儲けの方法が現時点では見えていないことだ。
従来の検索エンジンであれば検索結果のリンク・リストと並んで表示される「検索連動広告」がグーグルの主な収入源だった。その額は2022年に1620億ドル(約20兆円)に達したと見られている。
ところが対話型AIではユーザーの求める回答が直に表示されてしまうので、それらの広告をクリックする必要性が大幅に低下すると見られている。つまりグーグルは従来のビジネス・モデルを自ら破壊する恐れもある。
それでも敢えて、今回の動きに出たのは、すでにライバルのマイクロソフトが同社の検索エンジンBingに対話型AI機能を組み込んでしまったからだ。この対話型AIのベースにある技術は今、世界的な人気のChatGPTが採用しているGPT-4と呼ばれる大規模言語モデル(LLM)を検索・ビジネス用にカスタマイズしたものと見られている。
このため放っておけばグーグルはChatGPTの様に便利な対話型AI機能を組み込んだBingに検索市場を奪われてしまう恐れが出てきた。そこで自らの主力製品であるグーグル検索にも自社製の対話型AI機能を組み込んできたのだ。
元々、ChatGPTなど対話型AIのベースとなる「トランスフォーマー」と呼ばれる技術(方式)はグーグルの研究チームが2017年頃に開発したもの。さらに、この方式を採用したLLM技術の研究開発でもグーグルはIT業界をリードしてきた。
しかし、これら対話型AIやLLMは、その研究開発段階で、しばしば誤った回答や「(AIの)幻覚」と呼ばれるような捏造情報、さらには性的・人種的な偏見などを返してきたため、グーグルはLLMの製品化をこれまで自重してきた経緯がある。
しかし(前述のように)マイクロソフトがChatGPTの開発元であるOpenAIと提携して、この技術をBingに組み込んで検索エンジン市場の奪取に乗り出してきた。これに対抗するため、グーグルもLLMや対話型AIの技術を使って検索エンジンを強化せざるを得なくなった。それが今回の動きの背景にある。
将来、対話型AIの導入によって検索連動広告の収入が大幅に減少した場合、グーグルは恐らくクラウド事業の拡充でその埋め合わせを図るのではないかと見られている。
グーグルが対話型検索エンジンのベース技術として採用しているLLMは「PaLM 2」と呼ばれる。これらのLLMは別名「基盤モデル(Foundation Model)」とも呼ばれ、対話型AIをはじめ生成AIの文字通り「基盤」となる技術だ。
グーグルは今後、この「PaLM 2」のような基盤モデルをクラウド・サービスとしてクライアント(顧客企業)に有料で提供していく。クライアントはこの基盤モデルを自社データでカスタマイズして独自の生成AIを開発し、それを自社の業務で使用したり、あるいは新製品として販売していくことができる。
一方、グーグルはこれによるクラウド事業の収益増で、従来の検索連動広告の収入減少を埋め合わせる算段ではないかと見られている。
マイクロソフトは対話型AIを搭載した新型Bingを一般公開
グーグルがこうした対話型の検索エンジンを発表する直前、マイクロソフトも対話型AIを搭載した新型Bingを一般公開した。メール・アドレスなどでユーザー登録すれば誰でも使える。ただ、現時点では本格的な製品というより、試作版としてリリースして一般ユーザーによるテスト利用を促すのが主な目的だ。そのフィードバックを今後の開発に活用して、最終製品のリリースに漕ぎ着ける構えだ。
新型Bingは基本的に画面を二分割して使う。左側の画面では従来と同様の検索エンジン、右側の画面では対話型AIが使える。ただ、画面モードを切り替えると、全面が検索エンジンあるいは対話型AIとしても使うことができる。
対話型AIでは、たとえば「2022年の円ドル・レートの最高値、最安値、平均値を教えて」といった形でダイレクトな質問をぶつけると、ずばりとその回答が返ってくる(図2)。
その答えの真下には、「詳細情報」として為替レートの引用先のウェブ・サイト(リンク・アドレス)が表示される(図2では隠れて見えない)。これらをクリックすれば、それらのサイトに移動して情報源を確認することができる。
新型Bingの対話型AIは、他にも「画像生成」や「メールの自動作成」、「文書の要約」など多彩な機能を備えている。試しに筆者が「二匹の子猫が将棋を指している絵を描いて」とリクエストすると、それらしい画像が生成された(図3)。因みに、ここにはOpenAIの画像生成AI「DALL-E 2」の技術が採用されている。
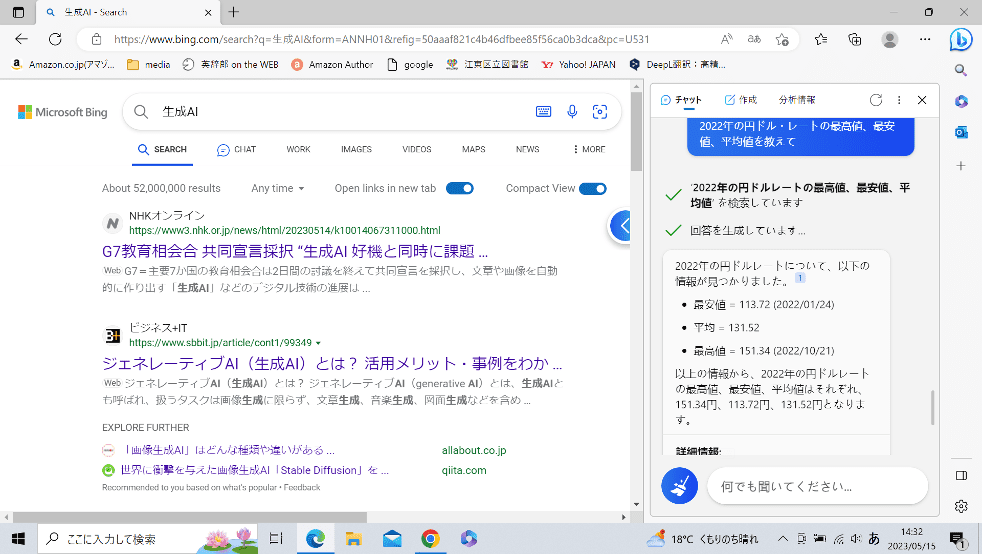
出典:https://www.bing.com/
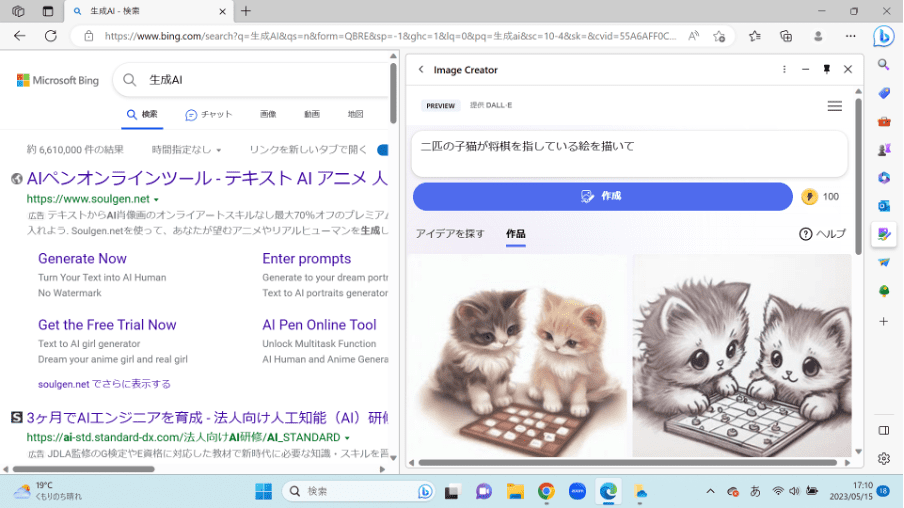
出典:https://www.bing.com/
グーグルと同様にマイクロソフトも、こうした新しい検索エンジンのビジネス・モデルは未だ見出していない模様だ。ただ、世界の検索エンジン市場でグーグル検索の占めるシェアが優に90パーセント以上に達しているのに対し、マイクロソフトBingの市場シェアは僅か3パーセント程度。
マイクロソフトは検索エンジン市場で言わば「失うものがない」状態なので、「検索エンジンに対話型AIを組み込む」といった思い切った動きに出ることに躊躇はなかった。そこからどのようにお金を儲けていくかは走り出してから考えればいい。まずはグーグルのシェアを奪うことが先決だと考えたのであろう。
ウェブ上のトラフィックが劇的に変化する
グーグルが検索エンジンの試作版の使用テストを終え、本格的な製品(サービス)として一般公開するのは恐らく来年に入ってからだ。
一方、マイクロソフトはグーグルよりも早く動く必要があるので、今年中には新型Bingを最終的に製品化してリリースしてくるかもしれない。
いずれにせよ恐らく今後半年から1年程度の期間をかけて、検索エンジンは従来の姿から対話型AIを中心とする全く新しい姿へと変貌を遂げる。
この影響を真っ先に受けるのはウェブ・メディアではないかと見られている。
新聞社や出版社、さらにはIT関連業者をはじめ各種メディアが運営するウェブ・メディアは従来、グーグルなどの検索エンジンから流入してくるトラフィックに大きく依存してきた。
つまりグーグルの検索結果として画面に表示されるウェブ・メディアのリンクをユーザーがクリックして、それらのサイトに移動することで、ウェブ・メディアのページ・ビューが増加し、それによって相当の広告収入を稼ぐことができた。
ところが近い将来、グーグルやBing等の検索エンジンが対話型AIに切り替われば、検索エンジンのサイト上でユーザーの求める回答や情報が得られてしまう。つまり検索エンジンのサイトが自己完結的になってしまうので、従来ウェブ・メディアに流れ込んでいたトラフィックが(完全に消失することはないにしても)激減することが懸念されている。
これは日本や米国をはじめ各国の報道関係者の間で、今、愁眉の急となっている問題だ。グーグルはこうした懸念の火消しに躍起になっているとされるが、具体的な対策は見えてこない。
このため、メディア各社は今後、グーグルやマイクロソフト、さらにOpenAIなど対話型AIを提供するIT企業に対し、自社製コンテンツの使用料金を求めていくのではないかと見られている。
ChatGPT、あるいはグーグル検索やBingなどのベースにあるLLM(大規模言語モデル)は、ウェブ上で収集した膨大なデータを機械学習することによって開発された。こうした学習の成果として、対話型AIはユーザーと流ちょうに会話したり、ユーザーが求める答えをずばりと返すことができる。
これら学習用データには、メディア各社の記事や報道写真など各種コンテンツも大量に含まれている模様だ。しかし、その大半はメディア各社に無断で使われている上、その対価も支払われていない。今後、メディア各社はこの対価をコンテンツ使用料という形でOpenAIやグーグルなどIT企業に要求していく可能性が高い。それによって自社のウェブ・メディアのトラフィック、つまり収入の減少を補っていくと見られている。
ただ、これらのIT企業がメディアの要求に素直に応じるという保証はない。少なくとも、ウェブ・メディアへのトラフィックの減少が目に見える形で表れてくるまでは、IT企業側が動くことはないだろう。今年から来年にかけて、メディア各社とIT企業の間で緊張が高まっていく可能性がある。
さらにこうした問題は、ウェブ・メディアだけでなく中小のEコマース事業者などについても当てはまりそうだ。これらの事業者も、これまで同じくグーグル検索から流入してくるトラフィックに多かれ少なかれ依存してきたからだ。
しかし今後、グーグル検索などが対話型AIを導入することによって、Eコマース・サイトへのトラフィックも減少する恐れがある。ウェブ・メディア程のインパクトは見られないかもしれないが、それでもウェブ上のトラフィックが大きく変化することはまず間違いない。これはEコマース事業者にも相応の影響を与えるはずだ。今後、半年から1年程度の猶予期間に、何らかの対策を講じる必要が出てきそうだ。
KDDI総合研究所リサーチフェロー 小林 雅一
◼️関連コラム
第4回 ChatGPTなど生成AIは私達の仕事や雇用をどう変えるか(2023-4-10)
https://rp.kddi-research.jp/atelier/column/archives/1276
第3回 生成AIが著作権侵害などで訴えられる――人間の作品から学んで創る人工知能はクリエーターやジャーナリストの敵となるのか?(2023-3-16)
https://rp.kddi-research.jp/atelier/column/archives/1192
第2回 話題のテキスト生成AI「ChatGPT」の性能評価――確かに回答には誤りが多いが、本来の実力を見極めるには今しばらく時間が必要(2023-2-7)
https://rp.kddi-research.jp/atelier/column/archives/1115
AIブームの第2波を巻き起こすGenerative AI:第1回 画像生成AIとは何か(2023-1-19)
https://rp.kddi-research.jp/atelier/column/archives/1091