世界のAI開発をリードする米OpenAIは2024年12月、約2週間に渡る新製品発表イベントの締め括りに推論型の次世代モデル「o3」を発表した[1]。
「o3」は文字通り推論能力(思考力)に優れ、それを効果的に活用することにより、ソフト開発やコンピュータ・プログラミングの性能評価試験では前モデルのo1よりも44~47パーセントも成績が上がった(図1)。また数学や(博士課程レベルの)科学の試験でも、正解率が12~16パーセント上がったという(図2)。
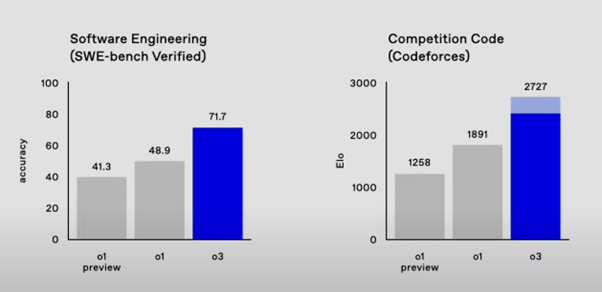
出典:https://openai.com/12-days/
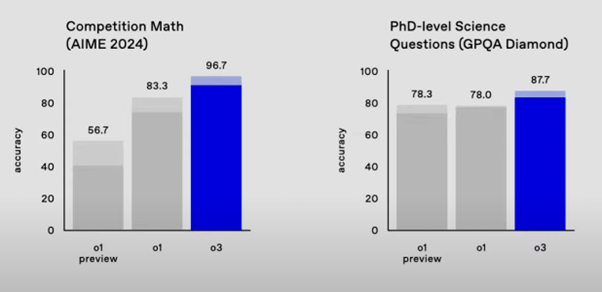
出典:https://openai.com/12-days/
一般のユーザーにはピンと来ない
この「o3」やそれを小型化した「o3 mini」は2025年初旬からリリースされ、実際に私達が使えるようになるという。ただ、たとえ使えるようになっても(筆者を含む)一般のユーザーには、そのありがたみがいまひとつよく分からないかもしれない。
これは以前に「o1」がリリースされたときにも感じたことだが、その高度な推論能力を実感できるユーザーが一般人の中にどれほどいるのか?
確かに一部では「東大入試問題の数学をo1に解かせてみたら、半分くらいで正解を出しました」などという声も聞かれたが、大半の人たちにとっては「そう言われてもピンと来ない」というのが、むしろ本音ではないか。(前掲の)o3のテスト結果もそうだが、要するに「凄い能力を備えている」と言われても、私達が日常生活や普段の仕事で実際に使う機会があまりないから実感が湧かないのである。
逆にコンピュータ・プログラマーや数学者、あるいは化学者や生物学者など一部の専門職の人たちは現在の「o1」あるいは今後の「o3」などをフルに使いこなして、自らの仕事に役立てることができるかもしれない。しかし、これらの専門職が世の中の職業全体に占める割合はせいぜい数パーセント程度であろう。それ以外の大多数の職種では「o1」や「o3」のような推論型モデルは正直オーバースペック、つまり「持て余し気味」であるように筆者には思われる。
開発が難航する次世代の基盤モデル「GPT-5」
そもそもo1やo3のような推論型モデルは、OpenAIが最初から計画的に開発したものではなく、むしろ苦肉の策として生まれた節もある。OpenAIは現在、従来の基盤モデル「GPT-4o」に代わる次世代の「GPT-5(開発コードネームはOrion:オリオン)」を全力で開発中だが、米国メディアの報道によれば、その開発作業は難航しているという。
当初の計画では、GPT-5は2024年に完成してリリースされるはずだったが、それが2025年以降にずれこんだという説も聞かれる。o1やo3などは、そこに至るまで当座をしのぐピンチヒッターのようにも見える。
ここまでの経緯を振り返ると、まずChatGPTがリリースされた2022年11月当時、そのベースとなる基盤モデル(Foudation Model)はGPT-3.5だった。ChatGPTが世界的なブームを巻き起こすのは2023年に入ってからだが、その年の3月にOpenAIはその数年前から開発を進めてきたGPT-4を完成・リリースして、これをGPT3.5に代わる(ないしはそれと並んで提供される)新たな基盤モデルとしてChatGPTに組み込んだ。
これとほぼ同時に、同社は早くもGPT-4(ないしはその改良版GPT-4o)に代わる次世代モデルGPT-5(オリオン)の開発に着手していた。前述のように、それは本来2024年にリリースされる予定だったが、実際には完成が延期に延期を重ね、結局2025年以降にずれこんでしまった。
従来のAI開発を支配してきた経験則が限界に
何故、これほど開発が難航しているのか?
その主な理由は、これまでGPTシリーズのような大規模言語モデル(Large Language Model: LLM)の開発を支配してきた「スケール則(Scaling law)」がそろそろ限界に近付いているからだと見られている。
スケール則とは元々、米ジョンズ・ホプキンズ大学の理論物理学教授でOpenAIの研究者でもあったJared Kaplan(現在は米アンソロピックに所属)が提唱した一種の経験則である。それによれば「LLMはその規模(つまりLLMを構成するパラメーターの数)を大きくすればするほど、またそれが機械学習するテキスト・データなどの量を増やせば増やすほど、その性能は指数関数的(つまり天井知らず)に上昇する」という。
中でも機械学習、つまりLLMのような大規模AIのトレーニングに使われるデータ量はAIの性能を左右する最も重要な要素と見られていた。
2018年の「GPT(Generative Pre-trained Transformer)-1」に始まるGPTシリーズの開発に際して、OpenAIはウェブ(インターネット)上から手当たり次第に(デジタル化された)「書籍」「新聞記事」「コンピュータ・プログラム」「(数学や自然科学などを中心とする)学術論文」など大量のテキストデータを集めてきて、これをAIに食わせて消化(機械学習)させた。これによって、LLMのような現代AIは人知が及ばぬ膨大な知識と同時に、流暢な言語能力も獲得できたのである。
しかしGPT-4の開発を終える頃には、OpenAIはウェブ上で集められる限りのデータはほぼ集めて使い尽くしてしまった。つまりオリオン(GPT-5)のような次世代LLMの開発に必要な機械学習用データがほとんど枯渇してしまったのである。これはOpenAIに限らず、同社と競合するグーグルやメタのようなビッグテック、あるいはスタートアップ企業のアンソロピックなど各々独自のLLMを開発するAI企業に共通する悩みである。
もっとも、これは厳密には「スケール則」が限界に達したと言うより、それに必要な学習用データが足りなくなってきた、と言うべきかもしれない。が、いずれにせよ次世代の基盤モデルGPT-5をより高性能で賢くするためには、従来のように「LLMの規模を大きくして、より大量のデータをウェブから搔き集めて機械学習させればいい」という単純なやり方が通用しなくなったのである。
限界を突破する2つの方法とは
この問題に対し、OpenAIの研究者達は主に二つの対策を講じた。一つは機械学習に必要なデータがウェブ上で足りなくなったのであれば、それを補うデータを人力作業で強引に作り出すことである。たとえば多数のライターを一時的に雇って文章を書かせたり、プログラマーにコードを書かせたり、数学者や科学者に数学や物理の難問を解かせたりする。これらの知的生産物をGPT-5のようなLLMの機械学習用データとして活用するのである。
これには別のやり方もある。それは「合成データ(synthetic data)」と呼ばれるもので、有り体に言えば「(人間ではなく)AIが作り出したデータ」のことである。つまりGPT-5のようなAIの機械学習用データとして、他のAIが出力したデータ(文章やプログラム、数式等々)を活用するというアイディアである。
以上が「機械学習用に足りなくなったデータを何らかの方法で補う」というやり方だが、もう一つの柱となる対策は「機械学習とは別の方法でAIを賢くする」という方法である。GPT-5のようなLLMの能力は、主に「トレーニング」と「トレーニング後(post -training)」の2段階に分けて育まれる。
「トレーニング」とは機械学習を中心とするAI開発の前工程である。これに対し「トレーニング後」とは、機械学習を終了したLLMがユーザーのプロンプトに応じて何らかのコンテンツを生成する後工程である。
後者の工程は一般に「inference(推論)」や「reasoning(推論)」(つまり日本語訳は同じ)とも呼ばれるが、OpenAIの研究者らはこの推論工程を強化することでGPT-5の性能をアップしようとした。たとえばユーザーから「これこれこういう数学の問題を解いてください」等のプロンプトを受けたとき、一つではなく複数の解法(思考経路)を同時並行的に探索し、その中からベストな結果を最終的な回答として返してくる方法だ。
一般にLLMには「ハルシネーション(幻覚)」と呼ばれる誤った解答を出力する傾向が指摘されているが、そのように推論工程を強化することで、より精度の高い回答を返すことができるようになる。
ただし、このやり方には複数の思考経路を同時に探索・評価することから、プロセッサなどのハードウエアに大きな負荷がかかるので計算に時間がかかる。こうした問題を抱えてはいるが、それでもOpenAIの研究者達はなるべく精度の高い解答を得ることの方を優先したのだろう。
未完成のオリオンを推論型LLMと称してリリース
以上をまとめると、OpenAIの研究者らはスケール則の限界を突破するために:
- LLM開発の前工程にあたる機械学習用に足りないデータを大量の人力データや合成データで補う
- LLM開発の後工程にあたる推論工程を強化する
という二種類の対策によって次世代モデルGPT-5の開発に取り組んでいる。
これらのうち「2」の「推論工程の強化」は比較的順調に進んでいる。しかし「1」の「人力データと合成データの作成」は難航しているようだ。
その理由だが、まず機械学習用に大量の人力データを作成するには、ライターやプログラマー、数学者などを多数動員して一心不乱に作業させる必要がある。が、彼らも人間である以上、いくら報酬を貰ったとしても、AIの言わば餌となる文章やプログラム、計算式を書くのは、どうしてもモチベーションに欠けてしまうのである。このためOpenAIの研究者が期待するほどには、彼らの生産性は上がっていないようだ。
一方、片方のAIが出力する合成データをもう片方のAIの機械学習に利用するという方法は、機械学習の質が低下するという問題が指摘されている。それはAI研究者の間で「AIの近親交配」とも呼ばれ、それをやればLLMの性能はむしろ劣化すると見られている。
この問題に対しOpenAIの研究者らは、データ評価用のAIを別に開発し、これに合成データの質を評価させて、一定水準のクォリティに達した合成データだけを「オリオン(GPT-5)」のようなターゲットAIの機械学習に利用することにした。
しかし、こうした複雑な方式は実行に手間取り、肝心のクォリティも予め期待していた程には上がらなかった。これらの要因が積み重なって、オリオンつまりGPT-5は当初予定していた2024年の完成・リリースを延期せざるを得なくなったようだ。
しかしOpenAIは発足当初の「非営利の研究団体」から今や事実上の営利企業と化している。未だIPO(株式公開)こそ果たしていないものの、最近では約66億ドル(1兆円以上)もの資金をベンチャーキャピタル主導で調達しており、彼ら投資家の期待に応えるためには次々と何らかの新商品をリリースする必要がある。
本来2024年にリリースするはずだったGPT-5(オリオン)は「2」の「推論工程」の開発は順調に進んでいるが、逆に「1」の「不足するウェブ・データを人力データや合成データで補った機械学習」は遅々として捗らない。が、それでも何らかの新商品を世に送り出す必要に迫られたOpenAIは、恐らくは未完成のオリオンに「推論型」の「o1」や「o3」という名称をつけてリリースしたと見られる。いわば苦肉の策である。
この結果、o1やo3は確かにプログラミングや数学などに必要な思考力には長けているが、機械学習の部分が不十分であることから知識量に欠ける。さらにウェブ検索機能も備えていないことから、足りない知識をウェブ上のリアルタイム情報で補うこともできない。このため、プログラマーや科学者のような一部専門職を除く一般ユーザーには「帯に短し、たすきに長し」のような中途半端な存在になってしまったようだ。
「AI開発は今後停滞する」との見方は妥当か?
2025年以降、OpenAIはGPT-5やその後継モデルを次々とリリースしていくと見られる。が、その一方で同社をとりまく産業界や大学の研究者らの中には、「スケール則が限界に達した今、LLMを中心とするAI開発は今後しばらく停滞する」と見る人も少なくない。「既にGPT-5を開発する段階で苦戦しているOpenAIがその証拠だ」というのである。
これに対しOpenAIのサム・アルトマンCEOやNvidiaのジェイスン・フアンCEOなど主力企業の経営者らは「スケール則は未だ限界に達しておらず、LLMの性能が向上する余地は残されている。また仮に今後、限界に達したとしても、それに代わる全く新しい方法や技術がすぐに現れ、これまでの指数関数的なAIの成長は今後も続く」と強気な姿勢を崩していない。
実は今から数年前にも同様の議論がなされたことがあった。2012年頃に始まったディープラーニング・ブームでは、画像や音声などのパターン認識で飛躍的な性能の向上が見られたが、2018年頃にはそれが高原状態(plateau)に達し、このときにも「AI開発は今後しばらく停滞するのではないか」という声が一部専門家の間で聞かれた。
しかし当時、水面下ではOpenAIやグーグルなどが(ディープラーニング技術をベースに)従来とは全く異なるLLMという新しい技術の開発を進めていた。これにより「画像や音声などのパターン認識」から「人間の言葉を理解する自然言語処理」へとAI開発の中心が移行することになった。これが2022年11月に「ChatGPT」として結実し、現在の世界的なAIブームを巻き起こしたのである。
こうした近年の歴史を振り返ると、仮に「スケール則が限界に達した」という見方がある程度は的を射ていたとしても、水面下では恐らくそれに代わる新たな方式や技術が着々と開発されているはずだ。現在のAIブームは若干の浮き沈みはあるにせよ、基本的には今後とも急成長を維持すると見るのが妥当だろう。
KDDI総合研究所リサーチフェロー 小林 雅一
 脚注
脚注
[1] 現在、ChatGPTから使える推論型モデルは「o1」なので、それに代わる次世代モデルのネーミングとしては奇妙な感もある。この理由だが、OpenAIの発表によれば、たまたま他社のブランド名に「o2」という名称があるので、それとの混同を避けるため「o2」を飛ばして、いきなり「o3」にしたという。
関連コラム
第13回 グーグルの「AI Overview(AIによる概要)」が日本でも利用可能に(2024-09-05)
https://rp.kddi-research.jp/atelier/column/archives/5293
第12回 生成AIを開発するIT企業とメディアの複雑な関係(2024-06-13)
https://rp.kddi-research.jp/atelier/column/archives/5187
第8回 対話型AIがインターネットやパソコンの基本的UIになる時代が到来(2023-10-04)
https://rp.kddi-research.jp/atelier/column/archives/4845
第5回 グーグルやBingなどの検索エンジンは対話型AIの導入でどう生まれ変わるか(2023-05-22)
https://rp.kddi-research.jp/atelier/column/archives/4368